Pipeline IoT pour surveillance de capteurs
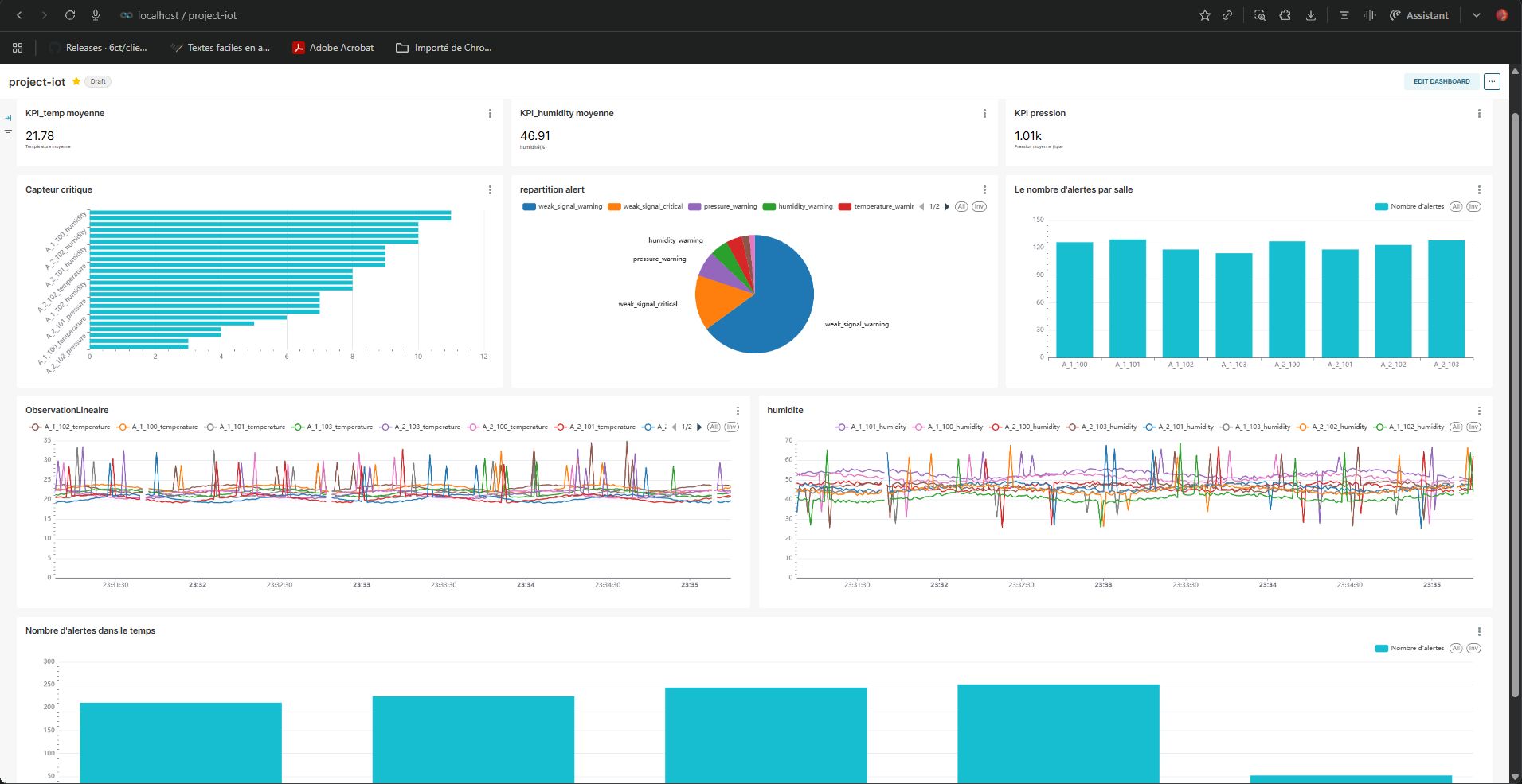
Pipeline ETL temps réel pour des flux de capteurs IoT (température, état des capteurs) avec Kafka et services dockerisés, détection d’anomalies et tableaux de bord dans Superset.
Pipeline ELT pour données e-commerce
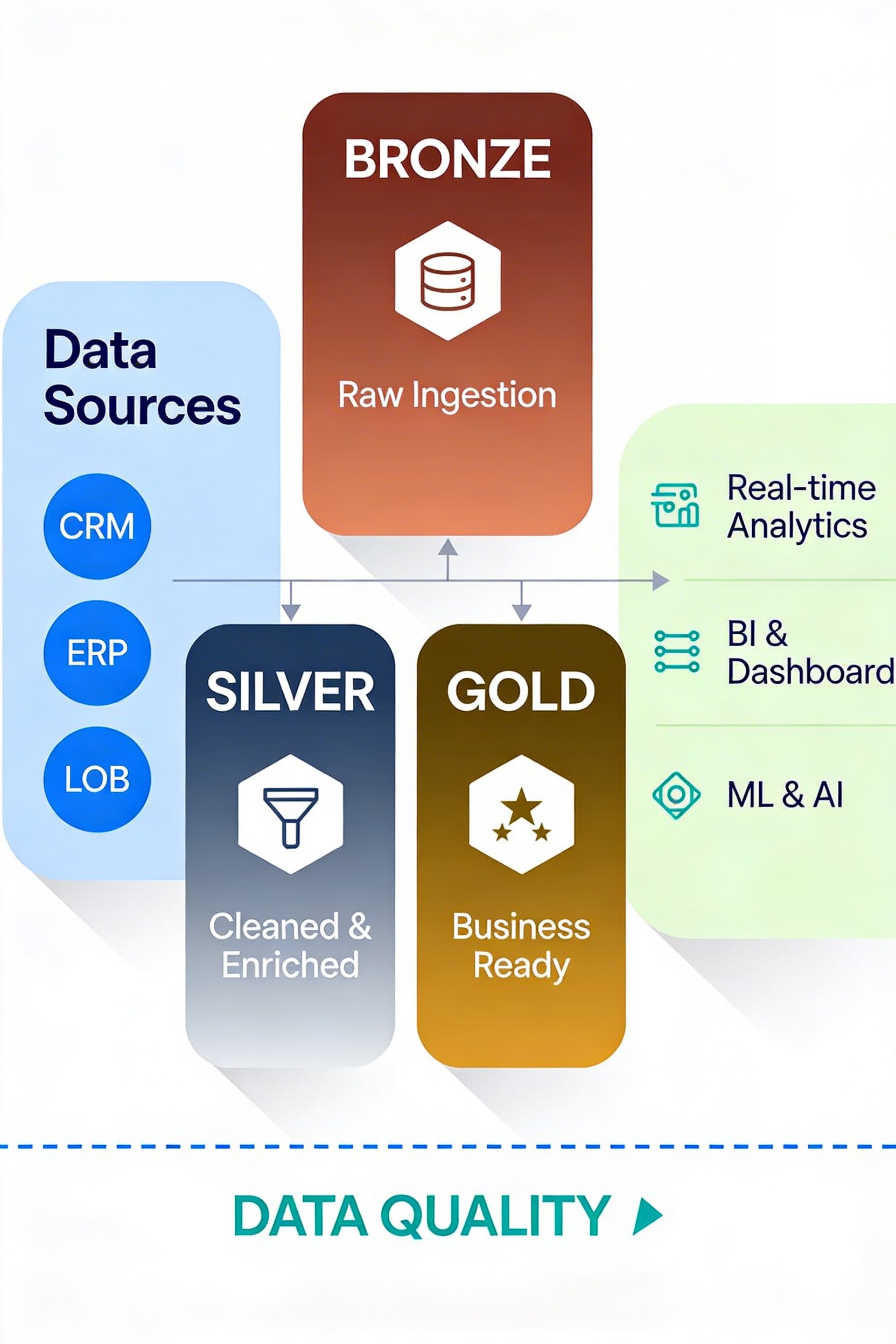
Ingestion du dataset Amazon sur Databricks, modélisation en couches médaillon avec dbt et exposition de tables analytiques dans BigQuery pour l’entraînement et le suivi de modèles de machine learning.
Évaluation de la qualité d’un graphe de connaissance avec un pipeline RAG
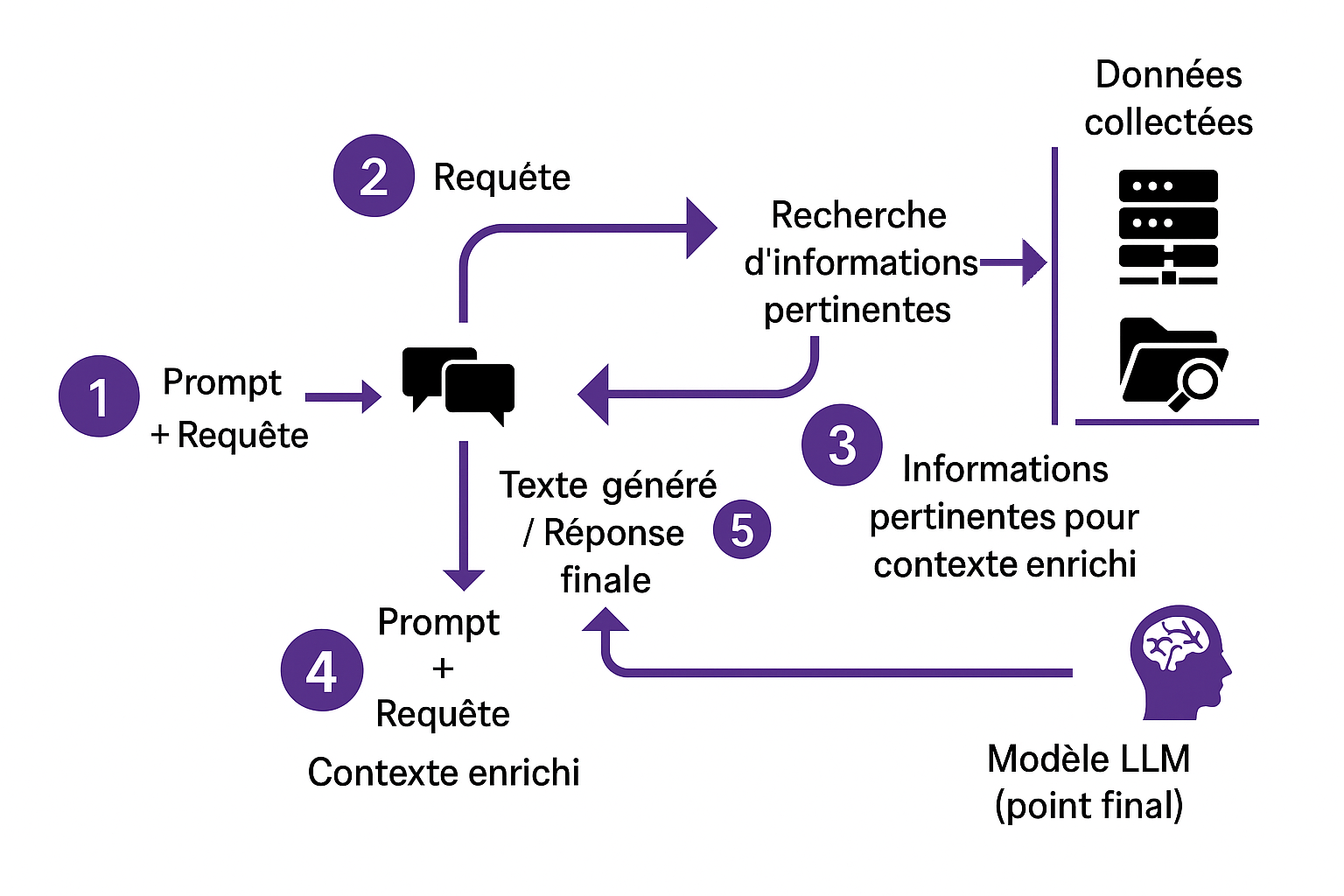
Mise en place d’un pipeline Retrieval-Augmented Generation (RAG) pour fact-checker automatiquement un graphe de connaissance à l’aide de grands modèles de langue (LLMs).
Détection de signes dépressifs dans les publications sur les réseaux sociaux
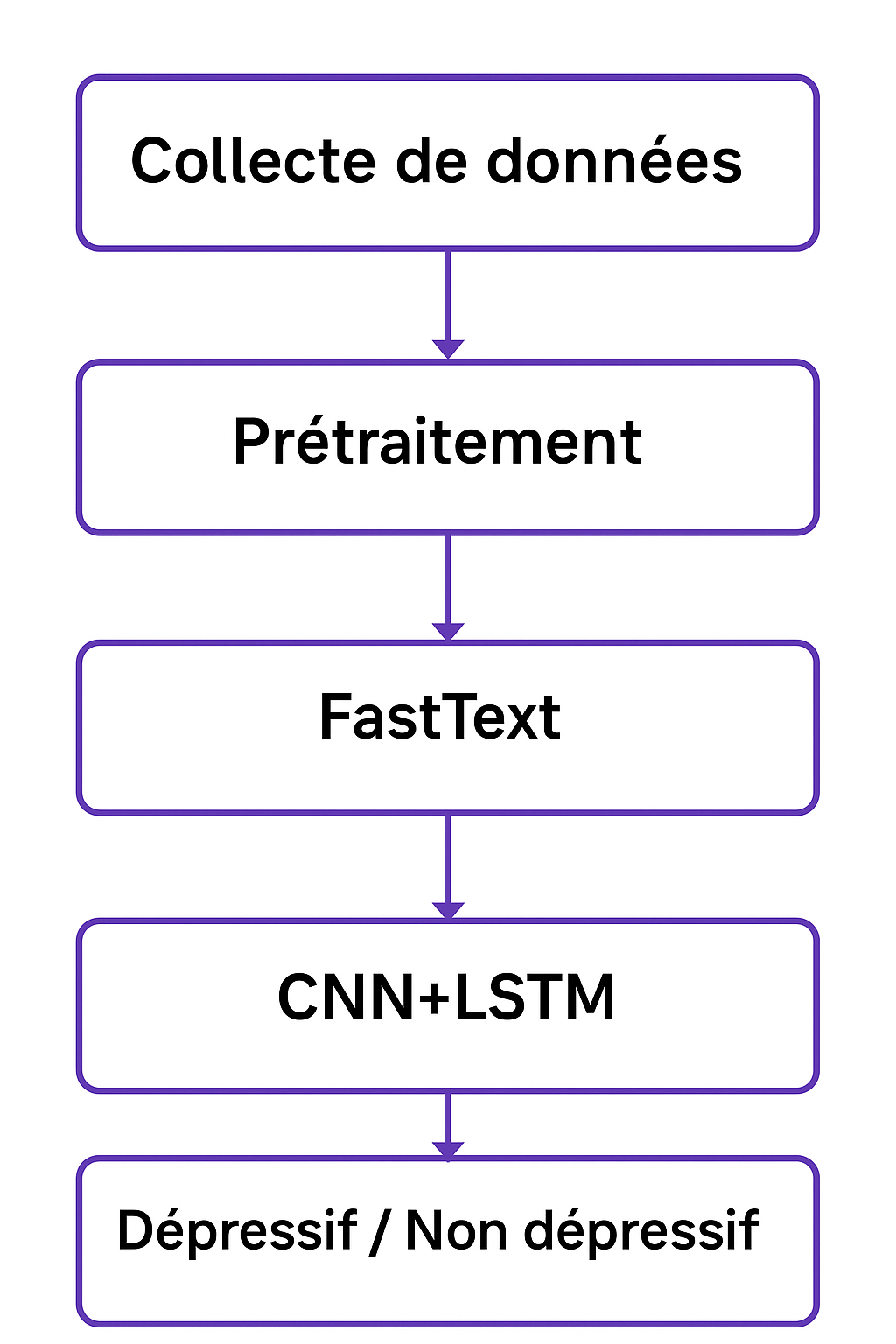
Projet visant à repérer automatiquement dans des tweets et des posts des indices de détresse psychologique afin d’alerter précocement les personnes concernées.
Jeu d’échecs en ligne

Développement d’un service web de jeu d’échecs permettant à deux joueurs humains de s’affronter, avec sauvegarde/reprise de parties et options de rejouer chaque coup.
Bayesian Database – Application Big Data
Conception et prototypage d'un logiciel Big Data (« Bayesian Database ») pour collecter, distribuer et analyser de grands volumes de données hétérogènes via Hadoop et Machine Learning.
Imputation des valeurs manquantes dans les séries temporelles d’électricité
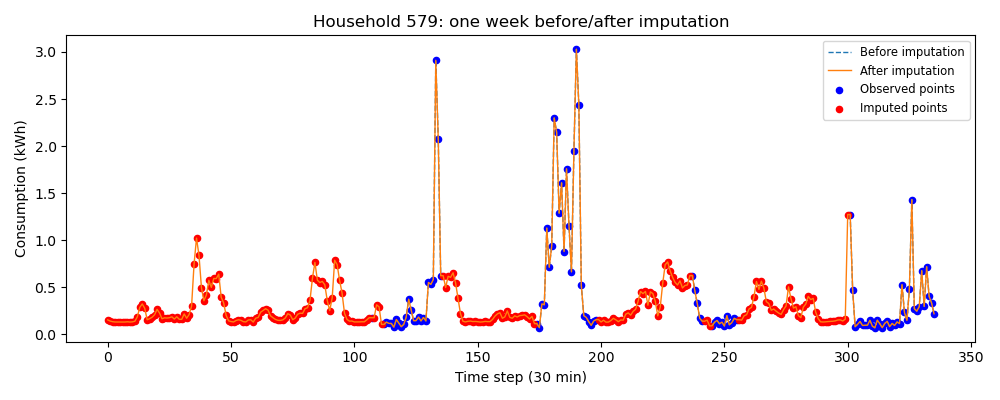
Comparaison de méthodes statistiques, ML et deep-learning pour combler les valeurs manquantes de relevés de consommation électrique résidentielle.
Arg-Solver : Résolution d'extensions d'argumentation

Implémentation d’un solveur Python pour les Abstract Argumentation Frameworks : calcul et décision d’extensions complètes et stables, ainsi que vérification de crédulité et scepticisme.